"Bilmiyorum" Diyebilen, Belgeye Dayalı Hukuk Yapay Zekâsı
- Hayal ve Asıl Sorun
- Hızlı Bir Yanlış Anlama Düzeltmesi: "Eğitmek" Değil
- Parçalar nasıl birleşiyor?
- 1) Belgeyi Metne Çevirmek ve PDF'teki Bug
- 2) Parçalama (chunking) Neden ve Nasıl?
- 3) Gömme: Metni Anlamı Koruyarak Sayıya Çevirmek
- 4) Vektör Arama: Gösterişsiz ama Yeterli
- 5) Üretim: Kaynağa Zorlanan Model
- Halüsinasyonu Gerçekten Engelliyor Mu? Bir Test
- Birden Fazla Belge Bulunca
- İki Motor: Bulut Haiku ile Yerel Model Arasında Geçiş
- Yoldaki dersler
- Nerede İşe Yarar ve Nasıl Ölçeklenir?
- 10 Milyon Belge: Büyük Veride Bizi Neler Bekliyor?
- Üç Modeli Yan Yana Koyunca
- Sonuç: Hukuk Yapay Zekası
- “Konuşmak kolay, kodu ver,” diyenlere:
İçindekiler
- Hayal ve Asıl Sorun
- Hızlı Bir Yanlış Anlama Düzeltmesi: "Eğitmek" Değil
- Parçalar nasıl birleşiyor?
- 1) Belgeyi Metne Çevirmek ve PDF'teki Bug
- 2) Parçalama (chunking) Neden ve Nasıl?
- 3) Gömme: Metni Anlamı Koruyarak Sayıya Çevirmek
- 4) Vektör Arama: Gösterişsiz ama Yeterli
- 5) Üretim: Kaynağa Zorlanan Model
- Halüsinasyonu Gerçekten Engelliyor Mu? Bir Test
- Birden Fazla Belge Bulunca
- İki Motor: Bulut Haiku ile Yerel Model Arasında Geçiş
- Yoldaki dersler
- Nerede İşe Yarar ve Nasıl Ölçeklenir?
- 10 Milyon Belge: Büyük Veride Bizi Neler Bekliyor?
- Üç Modeli Yan Yana Koyunca
- Sonuç: Hukuk Yapay Zekası
- “Konuşmak kolay, kodu ver,” diyenlere:

Görsel Gemini tarafından üretilmiştir.
Bir hukuk yapay zekâsının en büyük sorunu hız değil, güven: Model emin bir tonla uydurursa, yani halüsinasyon üretirse tek bir madde numarası bile davayı yakar. Bu bayram tatilinde bu sorunu çözmeye çalışan bir RAG sistemi yazdım ve Türkçe hukuki metinlerde üç güncel modeli -Claude Haiku 4.5, Gemma 4 ve DeepSeek-R1- kıyasladım.
Hayal ve Asıl Sorun
Elimde devasa bir hukuki belge arşivi var. Hayalim basit: Bir hukukçu ya da sıradan biri soru sorsun, doğru cevabı dayanağıyla alsın.
Halüsinasyon burada bir detay değil, projenin var olma sebebi. Şimdilik bütün arşivle değil, eklediğim birkaç belgeyle test yapacağım.
Hızlı Bir Yanlış Anlama Düzeltmesi: "Eğitmek" Değil
Yaygın refleks şu: “Modeli kendi belgelerimle eğiteyim.”
Oysa ince ayar (fine-tuning), bilgiyi modelin ağırlıklarına bulanık ve geri getirilemez biçimde gömer. Üslup öğretir ama olguları güvenilir biçimde ezberletmez; halüsinasyonu çoğu zaman azaltmaz, hatta artırabilir.
Doğru araç RAG (retrieval-augmented generation): Bilgi modelde değil, dışarıda bir arşivde durur; soru anında ilgili parçalar bulunup modele verilir. Böylece bilgi denetlenebilir, kaynaklanabilir ve belge eklemek saniyeler sürer. Yeniden eğitim yok.
Parçalar nasıl birleşiyor?
İki aşama var. Önce indeksleme (bir kez, belge ekledikçe tekrar), sonra her soruda arama + üretim. Tek tek bileşenler:
1) Belgeyi Metne Çevirmek ve PDF'teki Bug
.txt, .docx ve .pdf okunuyor. PDF'te beklemediğim bir sorun çıktı: İki popüler kütüphane, pypdf ve pdfplumber, Türkçe “i” harfini düşürüyordu:
“İçtihat” → “ çt hat”
Sebep, gömülü fontun bozuk ToUnicode/CMap eşlemesiydi; “i” glifi boşluğa map'leniyor, iki kütüphane de bu eşlemeye güvendiği için patlıyordu.
Çözüm, kendi font motoru olan pypdfium2 'ydi: Google'ın PDFium'u, BSD/Apache lisanslı. Gliften karaktere kendi çözümlemesini yaptığı için “i”yi kurtardı.
Not: Taranmış/görüntü PDF'lerde metin katmanı yoktur, OCR gerekir. Bu projedeki PDF'ler metin tabanlı olduğu için oraya hiç girmedim.
2) Parçalama (chunking) Neden ve Nasıl?
Belgeyi olduğu gibi gömemezsin: Gömme (embedding) modelinin bağlam sınırı var ve arama “belgenin tamamını” değil, “ilgili bölümü” döndürmeli. O yüzden metni parçalara bölüyorum. Nasıl böldüğüm kaliteyi belirliyor:
Gürültü temizliği: Sayfa numaraları, tarih başlıkları, URL'ler, portal kalıntıları regex kullanılarak atılıyor. Yoksa bunlar da vektöre karışıp aramayı kirletiyor.
Cümle bütünlüğü: Ham karakterde değil, cümle sınırında bölüyorum. Hedef ~1200 karakter, parçalar arası ~200 karakter örtüşme (bir kuralın sınırda ikiye bölünmesi hâlinde bağlam kopmasın diye).
Bu chunking yöntemi küçük belgeler için iş görür ama çok büyük belgelerde performansı düşebilir. Daha akıllı bir chunking sistemi gerekir tabii. Bunun için şu yazıma göz atabilirsiniz:

3) Gömme: Metni Anlamı Koruyarak Sayıya Çevirmek
Her parça, BAAI/bge-m3 ile 1024 boyutlu bir vektöre, yani metnin “anlam parmak izi”ne çevriliyor. bge-m3 çok dilli; Türkçeyi iyi biliyor, uzun metinde güçlü ve yerelde bedava çalışıyor: CPU/MPS, ikinci API anahtarı yok. Vektörleri normalize ediyorum.
4) Vektör Arama: Gösterişsiz ama Yeterli
Vektör veritabanı kullanmadım (Pinecone/Qdrant/Chroma yok). Bu ölçekte vektörleri tek bir NumPy dizisinde tutup kosinüs benzerliğiyle arıyorum. Normalize vektörlerde kosinüs benzerliği = iç çarpım olduğu için arama tek satıra iniyor:
scores = vectors @query_vec# (N,1024) · (1024,) -> (N,)
top = np.argsort(-scores)[:TOP_K] # en yüksek skorlu TOP_K parça
Gerçek skorlara bakmak öğreticiydi: “Kişisel veri nedir?”de alakalı parçalar 0.60–0.72, alakasız bir soru ise 0.42–0.46 bandında kaldı. Benzerlik mutlak değil, görece bir sinyal; bu yüzden MIN_SIMILARITY eşiğiyle (0.35) çöpü eliyorum.
5) Üretim: Kaynağa Zorlanan Model
Getirilen parçalar, kaynak etiketleriyle birlikte tek bir istemde modele veriliyor. Sihir burada: sıkı sistem talimatı + temperature = 0.
Yalnızca verilen belgeleri kullan. Genel hukuk bilginden veya tahminden ASLA yararlanma.
Belgedeki bir kuralı sorudaki duruma uygulayabilirsin (doğrudan çıkarım), ama belge dışı bilgi ekleyemezsin.
Her bilgiyi “Kaynak: dosya” biçiminde göster.
Cevap belgelerde yoksa aynen yaz: "Bu konuda sağlanan belgelerde bilgi bulamadım."
Halüsinasyonu Gerçekten Engelliyor Mu? Bir Test
En sevdiğim test: “İş sözleşmesi feshinde ihbar süresi kaç gündür?” diye sordum. Arşivdeki Yargıtay kararı belirli süreleri yazmıyordu. Modeller İş Kanunu'ndaki süreleri kendi ezberinden biliyordu ama belgede geçmediği için kullanmadı; “Bu konuda sağlanan belgelerde bilgi bulamadım,” dediler.
Bir hukuk aracında “bilmiyorum” diyebilmek, yanlış-ama-emin cevaptan kat kat değerlidir.
Birden Fazla Belge Bulunca
Arama, tüm arşivden en benzer TOP_K parçayı getirir; bunlar farklı belgelerden gelebilir, hepsi modele verilir ve model her bilgiyi ilgili belgeyle kaynaklandırır. Örneğin “kişisel veri”nin tanımı sorulduğunda iki ayrı belge geldi: tanım birinden, somut örnekler diğerinden. Soru değişince getirilen küme de değişiyor; sabit bir kural değil, anlam temelli bir seçim.
İki Motor: Bulut Haiku ile Yerel Model Arasında Geçiş
Cevabı kimin yazacağını tek satırlık bir ayar (config) belirliyor: bulut Claude Haiku ya da Ollama üzerinden yerel bir model (DeepSeek, Gemma). Arama katmanı zaten yerelde olduğu için motoru değiştirmek mimariyi bozmuyor.
Bu yazıda kıyasladığım üç model:
Claude Haiku 4.5: bulut; model kimliği claude-haiku-4-5
Gemma 4: e4b varyantı, ~8B parametre, Q4_K_M nicelemesi (yerel, Ollama: gemma4:e4b)
DeepSeek-R1 8B: Llama tabanlı, damıtılmış (distill) model (yerel, Ollama: deepseek-r1:8b)
İki ucun da gerçeği var: Haiku en tutarlı ve nüanslı ama API kredisi harcıyor ve belge buluta gidiyor. Yerel modeller bedava ve gizli, ama 16 GB RAM'de ikisini aynı anda belleğe sığdıramıyorsun; o yüzden kıyasta sırayla çalıştırıp bellekten bırakıyorum (keep_alive=0).
Yoldaki dersler
Bu sistemin tavanını çoğunlukla model değil, getirme (retrieval) belirliyor. Kaliteyi artırmak istiyorsan önce parçalama ve getirme katmanına yatırım yap.
“Çok dürüst” model de sorundur: ilk talimatım o kadar katıydı ki belgedeki bir kuralı uygulamaktan bile kaçınıyordu. “Belge-içi çıkarım serbest, belge-dışı bilgi yasak” ayarı dengeyi kurdu.
Detaylar ısırır: bir eksik karakter (PDF’teki “i”), bir fatura karışıklığı (abonelik ≠ API)… Mimari kararlar kadar bunlar da projeyi yapar/bozar.
“Kimsenin hiçbir şey bilmediği yerde bir insan her şeyi bilebilir.” Cevabını bir avukata doğrulatabildiğin soruları sormalısın ki modelin doğru cevap verip vermediğini kıyaslayabilesin.
Her zaman, her projede olduğu gibi: Basit başla, ölçtükten sonra büyüt.
Nerede İşe Yarar ve Nasıl Ölçeklenir?
Bu yaklaşım hukukla sınırlı değil: sözleşme arşivleri, uyum/regülasyon, kurumsal bilgi tabanları, müşteri destek dokümanları… “Kaynaklı ve uydurmayan cevap” gereken her yerde aynı kalıp çalışır. Peki bunu birkaç belgeden 10 milyon belgeye taşıyınca ne değişir?
10 Milyon Belge: Büyük Veride Bizi Neler Bekliyor?
Bu yalnızca daha güçlü sunucu meselesi değil. Bu projede bilinçli olarak aldığım birçok kısayol, o ölçekte doğrudan problem hâline gelecek.
Şu an vektörler NumPy içinde tutulup doğrudan taranıyor; küçük ölçekte yeterli olan bu yaklaşım, milyonlarca belgeye çıkıldığında hız ve bellek açısından çöker. Bu noktada ANN tabanlı vektör veritabanları, dağıtık indeksleme ve artımlı (incremental) güncelleme gerekir.
Belgelerin yapısı da işi değiştirir. Gerçek dünyada ham HTML, bozuk encoding, tablolar ve OCR gerektiren taranmış belgeler ayrı problem alanları açar. Chunking tarafında da sabit karakter uzunluğu yerine hukuki metni, madde/fıkra yapısını koruyarak bölmek gerekir.
Arama katmanında yalnızca anlamsal benzerlik yetmez. “5237 sayılı TCK madde 53” gibi sorgular tam eşleşme ister; bu yüzden semantik arama genellikle BM25 gibi klasik lafzi aramayla birlikte kullanılır.
Ama hukukta en sinsi problem teknik değil: zaman. Sistem halüsinasyon üretmese bile yürürlükten kalkmış bir maddeyi güncelmiş gibi gösterebilir. Yani model “uydurmuyor” olsa bile cevap hâlâ yanlış olabilir.
Üretim ortamında bunlara erişim kontrolü, KVKK, maliyet yönetimi, önbellekleme ve ölçümleme gibi operasyonel problemler de eklenir. Yine de temel mimari değişmez: oku, parçala, göm, getir ve kaynağa bağlı cevap üret. Değişen şey yalnızca kullanılan araçların ölçeğidir.
Üç Modeli Yan Yana Koyunca
Üç modeli de aynı belgeler ve aynı getirilen parçalarla (adil kıyas) beş soruda karşılaştırdım. Sorulardan biri tuzaktı. Cevabı hiçbir belgede yoktu ama üç model de bunu eğitim ezberinden biliyordu. Sonuç: Üçü de uydurmadı, “belgelerde yok” dedi. Yani anti-halüsinasyon yaklaşımı küçük yerel modellerde bile tuttu.
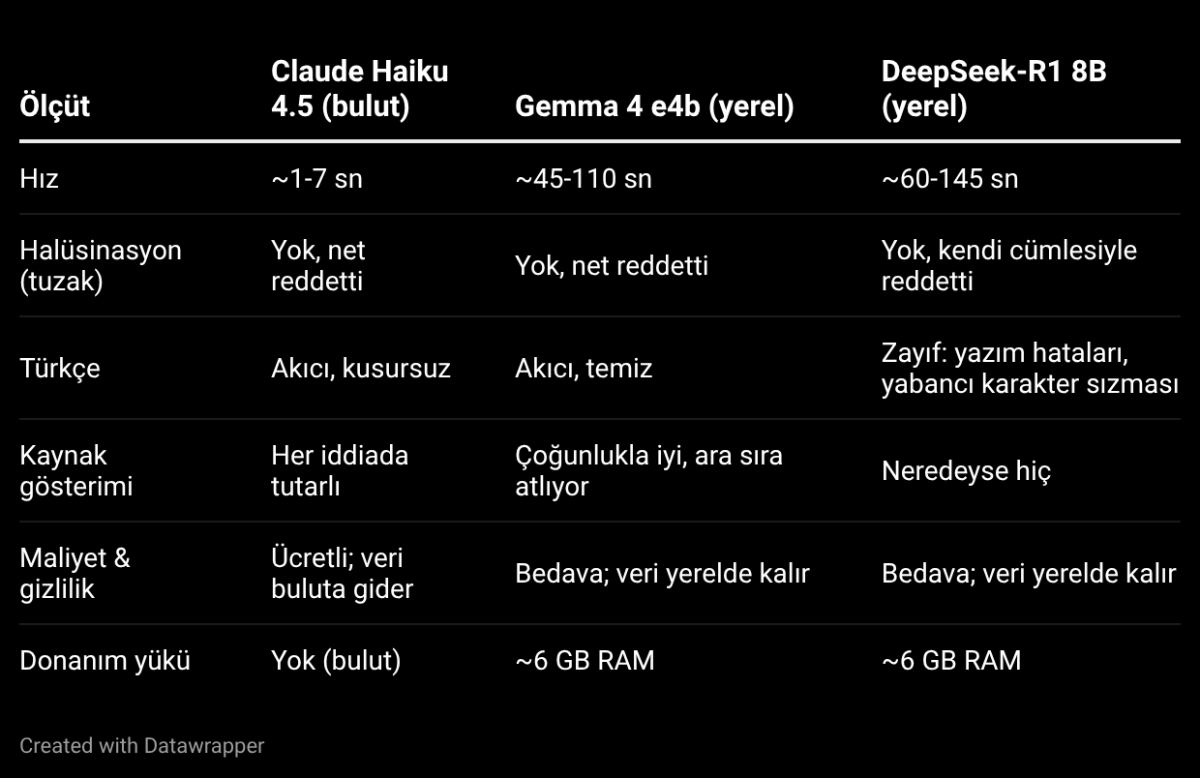
Datawrapper'da hazırlanmış tablo
Not: Hız kıyası eşit şartlarda değil. Haiku bulutta, yerel iki model 16 GB RAM'de GPU'suz çalışıyor; yine de aradaki fark büyük.
Kısa hüküm: Haiku hız, Türkçe ve kaynak disiplininde açık ara önde. Gemma 4 yerelde sürpriz derecede iyi; gizlilik ve bedavalık isteyene gerçek bir alternatif. DeepSeek-R1 güçlü muhakemeye sahip ama Türkçesi bozuluyor ve kaynak göstermeyi çoğu zaman atlıyor.
Tuzak soru: “İşveren feshinde ihbar süreleri kaç hafta?” (cevap hiçbir belgede yok):
Haiku: “…belgelerde bilgi bulamadım; metinlerde feshin çeşitli yönleri var ama ihbar süreleri yer almıyor.”
Gemma: “Bu konuda sağlanan belgelerde bilgi bulamadım.”
DeepSeek: “Belgelerde …ihbar süreleriyle ilgili bilgiler bulunmamaktadır.” (kendi cümlesiyle reddetti)
“Öney/Türkiye davasında mahkeme ne karar verdi?”:
Haiku: “2. maddenin usul yönünden ihlali; 20.000 avro manevi tazminat (Kaynak: Ek-13.pdf).” (en spesifik ve kaynaklı)
Gemma: “2. madde ihlali; maddi ve manevi tazminat…” (doğru yön, ama tutar ve kaynak yok)
DeepSeek: “…2. maddesinin usul yönünden ihlendiğini… kabul edilebilir olduğunu 认定 etti.” (özü doğru ama Türkçe bozuk, hatta Çince karakter sızmış)
Vergi (7524): “Yatırım fonu kazançlarında nasıl bir istisna getiriyor?”:
Haiku: “…kurumlar vergisinden istisnadır; taşınmaz kazançlarının en az %50’si için ek şart var (Kaynak: 7524.txt).” (somut ve kaynaklı)
Gemma: “…belirli şartlar altında vergi avantajları sağlanmıştır.” (doğru yön ama muğlak, tek kaynak)
DeepSeek: “…KVK’nın 5’inci maddesi 1’inci fıkrası (d) bendi…” (belgede geçmeyen, kaynağı kurulamayan bir madde atıfı ekledi)
“Düğün altınları kime ait, Yargıtay görüşünü değiştirdi mi?”:
Haiku: Eski ve yeni görüşü ayırıp yeni kararın tarihini ve esas/karar numarasını verdi (Kaynak: dugun.txt). En eksiksiz.
Gemma: Yeni kuralı maddeler hâlinde (anlaşma / örf ve âdet / genel kural) doğru aktardı, bolca kaynak gösterdi.
DeepSeek: Özü yakaladı ama “kural aynı kaldı, kapsam genişledi” diye biraz bulanıklaştırdı; kaynak yok.
Sonuç: Hukuk Yapay Zekası
Bu proje aslında bir fizibilite denemesiydi: birkaç belgede uydurmadan, kaynak göstererek çalışan bir sistemi uçtan uca kurup “milyonlarca HTML belgelik gerçek bir arşivde bunu nasıl yaparız?” sorusunu somut bir zemine oturtmak.
Cevap umut verici. Mimarinin omurgası (oku, parçala, göm, getir, kaynağa zorlanmış üretim) ölçekten bağımsız aynı kalıyor; değişen tek şey, yukarıda sıraladığım kısayolların yerine üretim sınıfı bileşenler koymak. Bunların hiçbiri çözülmemiş bir araştırma problemi değil, bilinen mühendislik kalemleri. Sabırla ve ölçerek tek tek ele alınır.
Kısacası milyonlarca belgeyi “bilmiyorum” diyebilen, yalan söylemeyen bir asistana dönüştürmek, uzun vadede sıkı çalışmayla ve iyi bir ekiple fazlasıyla mümkün görünüyor.
“Konuşmak kolay, kodu ver,” diyenlere:
Nasıl çalıştıracağınız README dosyasında detaylarıyla yazıyor. Bir yıldızınızı alırım artık.
Sıkça Sorulan Sorular
▸Hukuk yapay zekâsında halüsinasyon neden bu kadar kritik bir sorun?
Bir model yanlış ama emin bir tonla cevap verirse, tek bir hatalı madde numarası bile davayı olumsuz etkileyebilir. Bu yüzden hukuki yapay zekâlarda 'bilmiyorum' diyebilmek, yanlış-ama-emin cevaptan çok daha değerlidir. Güven, hızdan önce gelir.
▸Modeli kendi belgelerimle eğitmek (fine-tuning) yerine RAG neden tercih edilmeli?
Fine-tuning, bilgiyi modelin ağırlıklarına bulanık ve geri getirilemez biçimde gömer; olguları güvenilir şekilde ezberletmez, hatta halüsinasyonu artırabilir. RAG'da bilgi dışarıdaki bir arşivde tutulur, soru anında ilgili parçalar bulunup modele verilir; böylece bilgi denetlenebilir, kaynaklanabilir ve belge eklemek saniyeler sürer.
▸Türkçe hukuki metinlerde PDF okuma sırasında karşılaşılan 'i' harfi sorunu nasıl çözüldü?
pypdf ve pdfplumber kütüphaneleri, bozuk ToUnicode/CMap font eşlemesi nedeniyle Türkçe 'i' harfini düşürüyordu. Google'ın PDFium motorunu kullanan pypdfium2 kütüphanesi, gliften karaktere kendi çözümlemesini yaptığı için bu sorunu aşmayı sağladı.

